[Data Analysis] Autoencoder 이상 탐지
Autoencoder로 이상탐지 실습
Autoencoder 이상 탐지
Autoencoder란 입력 데이터를 주요 특징으로 효율적으로 압축(인코딩)한 후 이 압축된 표현에서 원본 입력을 재구성(디코딩)하는 딥러닝 기술입니다.
이를 통해 비정상적인 데이터가 입력되면 정상데이터만 학습한 Autoencoder는 noise부분은 제외하고 데이터를 출력할 것입니다. 출력된 데이터가 입력된 데이터와의 차이가 커지게 될 것이고 loss(=MSE)가 커져 threshold가 넘으면 비정상으로 판단할 것입니다.

위 그림과 같이 정상적인 데이터만 학습한 모델에 정상적인 데이터를 입력하고 출력값을 비교하면 Error가 크지 않는 것을 볼 수 있습니다.

반면, 비정상적인 데이터를 입력하고 출력값을 비교하면 Error가 크게 띄는 것을 확인할 수 있습니다.
Autoencoder 구조 요소
인코더(Encoder) : 차원 감소를 통해 입력 데이터의 압축된 표현을 인코딩하는 레이어로 구성됩니다. 일반적인 오토인코더에서 신경망의 숨겨진 레이어는 입력 레이어보다 점점 더 적은 수의 노드를 포함하며 데이터가 인코더 레이어를 통과할 때 더 작은 차원으로 ‘압축’되는 과정을 통해 압축됩니다.
병목 현상(Bottleneck) : 인코더 네트워크의 출력 레이어이자 디코더 네트워크의 입력 레이어로, 입력을 가장 압축적으로 표현한 것입니다. 오코인코더의 설계 및 학습의 기본 목표는 입력 데이터를 효과적으로 재구성하는 데 필요한 최소한의 중요한 특징(또는 차원)을 발견하는 것입니다. 그런 다음 이 계층에서 나타나는 잠재 공간 표현, 즉 코드가 디코더에 입력됩니다.
디코더(Decoder) : 인코딩된 데이터 표현을 압축 해제(또는 디코딩)하여 궁극적으로 데이터를 인코딩 전의 원본 형태로 재구성하며, 점진적으로 더 많은 수의 노드가 있는 숨겨진 레이어로 구성됩니다. 그런 다음 이렇게 재구성된 출력을 ‘근거가 되는 진실(대부분의 경우 단순히 원본 입력)’과 비교하여 오토인코더의 효율성을 측정합니다. 출력과 근거 진실의 차이를 재구성 오류라고 합니다.
- 장점
- 데이터의 Lable이 존재하지 않아도 사용 가능
- 고차원 데이터의 특징 추출 가능
- Autoencoder기반 다양한 알고리즘 존재(ex. 희소 오토인코더, 합성곱 오토인코더, 잡음 제거 오토인코더 등)
- 단점
- Hyper parameter(hidden layer) 설정이 어려움
- Loss(MSE)에 대한 threshold 설정이 어려움
Autoencoder 실습
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
import pandas as pd
import numpy as np
import plotly.graph_objs as go
import plotly.io as pio
pio.renderers.default = "colab"
from sklearn.metrics import accuracy_score, roc_auc_score, f1_score, precision_score, recall_score
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import MinMaxScaler
from sklearn.linear_model import LogisticRegression
from sklearn.manifold import TSNE
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
from torch.utils.data import TensorDataset, DataLoader, SubsetRandomSampler
from fastprogress import master_bar, progress_bar
from IPython.display import display
import random
1
2
3
4
5
6
7
8
SEED = 7
torch.manual_seed(SEED)
torch.cuda.manual_seed_all(SEED)
torch.backends.cudnn.deterministic = True
np.random.seed(SEED)
random.seed(SEED)
1
2
device = torch.device('cuda') if torch.cuda.is_available() else torch.device('cpu')
print(device)
1
cuda
1
2
data = pd.read_csv("creditcard.csv")
data
| Time | V1 | V2 | V3 | V4 | V5 | V6 | V7 | V8 | V9 | V10 | V11 | V12 | V13 | V14 | V15 | V16 | V17 | V18 | V19 | V20 | V21 | V22 | V23 | V24 | V25 | V26 | V27 | V28 | Amount | Class | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.0 | -1.359807 | -0.072781 | 2.536347 | 1.378155 | -0.338321 | 0.462388 | 0.239599 | 0.098698 | 0.363787 | 0.090794 | -0.551600 | -0.617801 | -0.991390 | -0.311169 | 1.468177 | -0.470401 | 0.207971 | 0.025791 | 0.403993 | 0.251412 | -0.018307 | 0.277838 | -0.110474 | 0.066928 | 0.128539 | -0.189115 | 0.133558 | -0.021053 | 149.62 | 0 |
| 1 | 0.0 | 1.191857 | 0.266151 | 0.166480 | 0.448154 | 0.060018 | -0.082361 | -0.078803 | 0.085102 | -0.255425 | -0.166974 | 1.612727 | 1.065235 | 0.489095 | -0.143772 | 0.635558 | 0.463917 | -0.114805 | -0.183361 | -0.145783 | -0.069083 | -0.225775 | -0.638672 | 0.101288 | -0.339846 | 0.167170 | 0.125895 | -0.008983 | 0.014724 | 2.69 | 0 |
| 2 | 1.0 | -1.358354 | -1.340163 | 1.773209 | 0.379780 | -0.503198 | 1.800499 | 0.791461 | 0.247676 | -1.514654 | 0.207643 | 0.624501 | 0.066084 | 0.717293 | -0.165946 | 2.345865 | -2.890083 | 1.109969 | -0.121359 | -2.261857 | 0.524980 | 0.247998 | 0.771679 | 0.909412 | -0.689281 | -0.327642 | -0.139097 | -0.055353 | -0.059752 | 378.66 | 0 |
| 3 | 1.0 | -0.966272 | -0.185226 | 1.792993 | -0.863291 | -0.010309 | 1.247203 | 0.237609 | 0.377436 | -1.387024 | -0.054952 | -0.226487 | 0.178228 | 0.507757 | -0.287924 | -0.631418 | -1.059647 | -0.684093 | 1.965775 | -1.232622 | -0.208038 | -0.108300 | 0.005274 | -0.190321 | -1.175575 | 0.647376 | -0.221929 | 0.062723 | 0.061458 | 123.50 | 0 |
| 4 | 2.0 | -1.158233 | 0.877737 | 1.548718 | 0.403034 | -0.407193 | 0.095921 | 0.592941 | -0.270533 | 0.817739 | 0.753074 | -0.822843 | 0.538196 | 1.345852 | -1.119670 | 0.175121 | -0.451449 | -0.237033 | -0.038195 | 0.803487 | 0.408542 | -0.009431 | 0.798278 | -0.137458 | 0.141267 | -0.206010 | 0.502292 | 0.219422 | 0.215153 | 69.99 | 0 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 284802 | 172786.0 | -11.881118 | 10.071785 | -9.834783 | -2.066656 | -5.364473 | -2.606837 | -4.918215 | 7.305334 | 1.914428 | 4.356170 | -1.593105 | 2.711941 | -0.689256 | 4.626942 | -0.924459 | 1.107641 | 1.991691 | 0.510632 | -0.682920 | 1.475829 | 0.213454 | 0.111864 | 1.014480 | -0.509348 | 1.436807 | 0.250034 | 0.943651 | 0.823731 | 0.77 | 0 |
| 284803 | 172787.0 | -0.732789 | -0.055080 | 2.035030 | -0.738589 | 0.868229 | 1.058415 | 0.024330 | 0.294869 | 0.584800 | -0.975926 | -0.150189 | 0.915802 | 1.214756 | -0.675143 | 1.164931 | -0.711757 | -0.025693 | -1.221179 | -1.545556 | 0.059616 | 0.214205 | 0.924384 | 0.012463 | -1.016226 | -0.606624 | -0.395255 | 0.068472 | -0.053527 | 24.79 | 0 |
| 284804 | 172788.0 | 1.919565 | -0.301254 | -3.249640 | -0.557828 | 2.630515 | 3.031260 | -0.296827 | 0.708417 | 0.432454 | -0.484782 | 0.411614 | 0.063119 | -0.183699 | -0.510602 | 1.329284 | 0.140716 | 0.313502 | 0.395652 | -0.577252 | 0.001396 | 0.232045 | 0.578229 | -0.037501 | 0.640134 | 0.265745 | -0.087371 | 0.004455 | -0.026561 | 67.88 | 0 |
| 284805 | 172788.0 | -0.240440 | 0.530483 | 0.702510 | 0.689799 | -0.377961 | 0.623708 | -0.686180 | 0.679145 | 0.392087 | -0.399126 | -1.933849 | -0.962886 | -1.042082 | 0.449624 | 1.962563 | -0.608577 | 0.509928 | 1.113981 | 2.897849 | 0.127434 | 0.265245 | 0.800049 | -0.163298 | 0.123205 | -0.569159 | 0.546668 | 0.108821 | 0.104533 | 10.00 | 0 |
| 284806 | 172792.0 | -0.533413 | -0.189733 | 0.703337 | -0.506271 | -0.012546 | -0.649617 | 1.577006 | -0.414650 | 0.486180 | -0.915427 | -1.040458 | -0.031513 | -0.188093 | -0.084316 | 0.041333 | -0.302620 | -0.660377 | 0.167430 | -0.256117 | 0.382948 | 0.261057 | 0.643078 | 0.376777 | 0.008797 | -0.473649 | -0.818267 | -0.002415 | 0.013649 | 217.00 | 0 |
284807 rows × 31 columns
1
2
# 최소 전처리
data['Time'] = data['Time'] / 3600 % 24
1
data['Class'].value_counts()
| count | |
|---|---|
| Class | |
| 0 | 284315 |
| 1 | 492 |
t-SNE 시각화
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
# t-SNE을 위한 데이터 샘플링
fraud = data.loc[data['Class'] == 1]
non_fraud = data.loc[data['Class'] == 0].sample(3000, random_state=SEED)
new_data = pd.concat([fraud, non_fraud]).reset_index(drop=True)
y = new_data['Class'].values
tsne = TSNE(n_components=2, random_state=SEED)
tsne_data = tsne.fit_transform(new_data.drop(['Class'], axis=1))
traces = []
traces.append(go.Scatter(x=tsne_data[y==1, 0], y=tsne_data[y==1, 1], mode='markers', name='Fraud', marker=dict(color='red')))
traces.append(go.Scatter(x=tsne_data[y==0, 0], y=tsne_data[y==0, 1], mode='markers', name='Non-Fraud', marker=dict(color='blue')))
layout = go.Layout(title = "t-SNE Scatter Plot",
xaxis_title="component1",
yaxis_title="component2")
fig = go.Figure(data=traces, layout=layout)
fig.show()
Autoencoder 학습
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
def get_dls(data, batch_sz, n_workers, valid_split=0.2):
d_size = len(data)
ixs = np.random.permutation(range(d_size))
split = int(d_size * valid_split)
train_ixs, valid_ixs = ixs[split:], ixs[:split]
train_sampler = SubsetRandomSampler(train_ixs)
valid_sampler = SubsetRandomSampler(valid_ixs)
ds = TensorDataset(torch.from_numpy(data).float(), torch.from_numpy(data).float())
train_dl = DataLoader(ds, batch_sz, sampler=train_sampler, num_workers=n_workers)
valid_dl = DataLoader(ds, batch_sz, sampler=valid_sampler, num_workers=n_workers)
return train_dl, valid_dl
1
2
3
4
5
6
7
8
9
10
11
12
13
14
# https://github.com/AnswerDotAI/fastprogress
def plot_loss_update(epoch, epochs, mb, train_loss, valid_loss):
""" dynamically print the loss plot during the training/validation loop.
expects epoch to start from 1.
"""
x = range(1, epoch+2)
y = np.concatenate((train_loss, valid_loss))
graphs = [[x,train_loss], [x,valid_loss]]
x_margin = 0.0001
y_margin = 0.0005
x_bounds = [1-x_margin, epochs+x_margin]
y_bounds = [np.min(y)-y_margin, np.max(y)+y_margin]
mb.update_graph(graphs, x_bounds, y_bounds)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
def train(epochs, model, train_dl, valid_dl, optimizer, criterion, device):
model = model.to(device)
mb = master_bar(range(epochs))
mb.write(['epoch', 'train loss', 'valid loss'], table=True)
train_loss_plot = []
valid_loss_plot = []
for epoch in mb:
model.train()
train_loss = 0.
for train_X, train_y in progress_bar(train_dl, parent=mb):
train_X, train_y = train_X.to(device), train_y.to(device)
train_out = model(train_X)
loss = criterion(train_out, train_y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
train_loss += loss.item()
mb.child.comment = f'{loss.item():.4f}'
train_loss_plot.append(train_loss/len(train_dl))
with torch.no_grad():
model.eval()
valid_loss = 0.
for valid_X, valid_y in progress_bar(valid_dl, parent=mb):
valid_X, valid_y = valid_X.to(device), valid_y.to(device)
valid_out = model(valid_X)
loss = criterion(valid_out, valid_y)
valid_loss += loss.item()
mb.child.comment = f'{loss.item():.4f}'
valid_loss_plot.append(valid_loss/len(valid_dl))
plot_loss_update(epoch, epochs, mb, train_loss_plot, valid_loss_plot)
mb.write([f'{epoch+1}', f'{train_loss/len(train_dl):.6f}', f'{valid_loss/len(valid_dl):.6f}'], table=True)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
class AutoEncoder(nn.Module):
def __init__(self, f_in):
super().__init__()
self.encoder = nn.Sequential(
nn.Linear(f_in, 100),
nn.Tanh(),
nn.Dropout(0.2),
nn.Linear(100, 70),
nn.Tanh(),
nn.Dropout(0.2),
nn.Linear(70, 40)
)
self.decoder = nn.Sequential(
nn.ReLU(inplace=True),
nn.Linear(40, 40),
nn.Tanh(),
nn.Dropout(0.2),
nn.Linear(40, 70),
nn.Tanh(),
nn.Dropout(0.2),
nn.Linear(70, f_in)
)
def forward(self, x):
return self.decoder(self.encoder(x))
1
2
3
4
5
6
7
EPOCHS = 10
BATCH_SIZE = 512
N_WORKERS = 0
model = AutoEncoder(30)
criterion = F.mse_loss
optimizer = optim.Adam(model.parameters(), lr=1e-3)
1
2
3
4
5
6
7
X = data.drop('Class', axis=1).values
y = data['Class'].values
X = MinMaxScaler().fit_transform(X)
X_nonfraud = X[y == 0]
X_fraud = X[y == 1]
train_dl, valid_dl = get_dls(X_nonfraud[:5000], BATCH_SIZE, N_WORKERS)
1
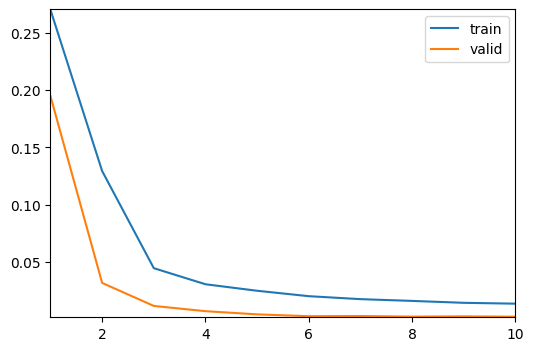
train(EPOCHS, model, train_dl, valid_dl, optimizer, criterion, device)
| epoch | train loss | valid loss |
|---|---|---|
| 1 | 0.270380 | 0.194823 |
| 2 | 0.129282 | 0.031349 |
| 3 | 0.044266 | 0.011216 |
| 4 | 0.030186 | 0.006618 |
| 5 | 0.024496 | 0.003836 |
| 6 | 0.019749 | 0.002219 |
| 7 | 0.017160 | 0.002380 |
| 8 | 0.015620 | 0.001863 |
| 9 | 0.013945 | 0.002094 |
| 10 | 0.013202 | 0.001787 |
평가
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
def print_metric(model, df, y, scaler=None):
X_train, X_val, y_train, y_val = train_test_split(df, y, test_size=0.2, shuffle=True, random_state=SEED, stratify=y)
mets = [accuracy_score, precision_score, recall_score, f1_score]
if scaler is not None:
X_train = scaler.fit_transform(X_train)
X_val = scaler.transform(X_val)
model.fit(X_train, y_train)
train_preds = model.predict(X_train)
train_probs = model.predict_proba(X_train)[:, 1]
val_preds = model.predict(X_val)
val_probs = model.predict_proba(X_val)[:, 1]
train_met = pd.Series({m.__name__: m(y_train, train_preds) for m in mets})
train_met['roc_auc'] = roc_auc_score(y_train, train_probs)
val_met = pd.Series({m.__name__: m(y_val, val_preds) for m in mets})
val_met['roc_auc'] = roc_auc_score(y_val, val_probs)
met_df = pd.DataFrame()
met_df['train'] = train_met
met_df['valid'] = val_met
display(met_df)
1
2
3
4
5
6
7
with torch.no_grad():
model.eval()
non_fraud_encoded = model.encoder(torch.from_numpy(X_nonfraud).float().to(device)).cpu().numpy()
fraud_encoded = model.encoder(torch.from_numpy(X_fraud).float().to(device)).cpu().numpy()
encoded_X = np.append(non_fraud_encoded, fraud_encoded, axis=0)
encoded_y = np.append(np.zeros(len(non_fraud_encoded)), np.ones(len(fraud_encoded)))
1
2
3
4
5
clf = LogisticRegression(random_state=SEED)
print('Metric scores for original data:')
print_metric(clf, X, y)
print('Metric score for encoded data:')
print_metric(clf, encoded_X, encoded_y)
1
Metric scores for original data:
| train | valid | |
|---|---|---|
| accuracy_score | 0.999008 | 0.999017 |
| precision_score | 0.852941 | 0.888889 |
| recall_score | 0.515228 | 0.489796 |
| f1_score | 0.642405 | 0.631579 |
| roc_auc | 0.968392 | 0.960051 |
1
Metric score for encoded data:
| train | valid | |
|---|---|---|
| accuracy_score | 0.998503 | 0.998490 |
| precision_score | 0.804598 | 0.772727 |
| recall_score | 0.177665 | 0.173469 |
| f1_score | 0.291060 | 0.283333 |
| roc_auc | 0.972581 | 0.983995 |