단일 모델 평가 시 데이터 셋 나누는 방법
- 공통적으로 Train, Validation, Test를 나누어 시작한다.
시간 순서가 없는 데이터 셋
K-Fold Cross Validation
- 데이터셋을 K개로 나누고 각 1개를 Validation셋으로 하고 나머지를 Train셋으로 모델을 학습한 평가지표를 평균으로 내어 측정하는 방법
1
2
3
4
5
6
| from sklearn.datasets import load_iris
from sklearn.model_selection import KFold
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
import pandas as pd
import numpy as np
|
1
2
3
4
5
| iris = load_iris()
data = iris.data
label = iris.target
data.shape
|
1
2
3
| kf = KFold(n_splits = 5)
kf.get_n_splits(data)
print(kf) # KFlod 확인
|
1
| KFold(n_splits=5, random_state=None, shuffle=False)
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| accuracy = []
dt = DecisionTreeClassifier()
for i, (train_index, validaiton_index) in enumerate(kf.split(data)):
print(f"K-Fold {i+1}")
x_train, y_train = data[train_index], label[train_index]
x_valid, y_valid = data[validaiton_index], label[validaiton_index]
dt.fit(x_train, y_train)
pred = dt.predict(x_valid)
acc = accuracy_score(y_valid, pred)
accuracy.append(acc)
print(f" Train: index={train_index}")
print(f" Test: index={validaiton_index}")
print(f"Accuracy : {acc}")
print(f"Average Accuracy : {np.mean(accuracy)}")
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
| K-Fold 1
Train: index=[ 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47
48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65
66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83
84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101
102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119
120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137
138 139 140 141 142 143 144 145 146 147 148 149]
Test: index=[ 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23
24 25 26 27 28 29]
Accuracy : 1.0
K-Fold 2
Train: index=[ 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
18 19 20 21 22 23 24 25 26 27 28 29 60 61 62 63 64 65
66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83
84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101
102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119
120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137
138 139 140 141 142 143 144 145 146 147 148 149]
Test: index=[30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53
54 55 56 57 58 59]
Accuracy : 0.9666666666666667
K-Fold 3
Train: index=[ 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35
36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53
54 55 56 57 58 59 90 91 92 93 94 95 96 97 98 99 100 101
102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119
120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137
138 139 140 141 142 143 144 145 146 147 148 149]
Test: index=[60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83
84 85 86 87 88 89]
Accuracy : 0.8333333333333334
K-Fold 4
Train: index=[ 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35
36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53
54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71
72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89
120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137
138 139 140 141 142 143 144 145 146 147 148 149]
Test: index=[ 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107
108 109 110 111 112 113 114 115 116 117 118 119]
Accuracy : 0.9333333333333333
K-Fold 5
Train: index=[ 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35
36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53
54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71
72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89
90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107
108 109 110 111 112 113 114 115 116 117 118 119]
Test: index=[120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137
138 139 140 141 142 143 144 145 146 147 148 149]
Accuracy : 0.7333333333333333
Average Accuracy : 0.8933333333333333
|
KFlod의 문제점
Train과 validation를 나누는데 label을 고려하지 않는다. 이는 label의 불균형이 발생할 가능성이 있다.
이에 Label을 균일하게 만드는 StratifiedKFold가 있다.
### StratifiedKFold
- Label을 균등하게 고려하여 데이터셋을 K개로 나누고 각 1개를 Validation셋으로 하고 나머지를 Train셋으로 모델을 학습한 평가지표를 평균으로 내어 측정하는 방법
1
| from sklearn.model_selection import StratifiedKFold
|
1
2
3
| skf = StratifiedKFold(n_splits=5)
skf.get_n_splits(data)
print(skf)
|
1
| StratifiedKFold(n_splits=5, random_state=None, shuffle=False)
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| stf_accuracy = []
for idx, (train_index, validation_index) in enumerate(skf.split(data, label)):
print(f"K-Fold {idx+1}")
x_train, y_train = data[train_index], label[train_index]
x_valid, y_valid = data[validation_index], label[validation_index]
dt.fit(x_train, y_train)
pred = dt.predict(x_valid)
acc = accuracy_score(y_valid, pred)
stf_accuracy.append(acc)
print(f" Train: index={train_index}")
print(f" Test: index={validation_index}")
print(f"Accuracy : {acc}")
print(f"Average Accuracy : {np.mean(stf_accuracy)}")
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
| K-Fold 1
Train: index=[ 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27
28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45
46 47 48 49 60 61 62 63 64 65 66 67 68 69 70 71 72 73
74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91
92 93 94 95 96 97 98 99 110 111 112 113 114 115 116 117 118 119
120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137
138 139 140 141 142 143 144 145 146 147 148 149]
Test: index=[ 0 1 2 3 4 5 6 7 8 9 50 51 52 53 54 55 56 57
58 59 100 101 102 103 104 105 106 107 108 109]
Accuracy : 0.9666666666666667
K-Fold 2
Train: index=[ 0 1 2 3 4 5 6 7 8 9 20 21 22 23 24 25 26 27
28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45
46 47 48 49 50 51 52 53 54 55 56 57 58 59 70 71 72 73
74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91
92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109
120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137
138 139 140 141 142 143 144 145 146 147 148 149]
Test: index=[ 10 11 12 13 14 15 16 17 18 19 60 61 62 63 64 65 66 67
68 69 110 111 112 113 114 115 116 117 118 119]
Accuracy : 0.9666666666666667
K-Fold 3
Train: index=[ 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
18 19 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45
46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63
64 65 66 67 68 69 80 81 82 83 84 85 86 87 88 89 90 91
92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109
110 111 112 113 114 115 116 117 118 119 130 131 132 133 134 135 136 137
138 139 140 141 142 143 144 145 146 147 148 149]
Test: index=[ 20 21 22 23 24 25 26 27 28 29 70 71 72 73 74 75 76 77
78 79 120 121 122 123 124 125 126 127 128 129]
Accuracy : 0.9
K-Fold 4
Train: index=[ 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
18 19 20 21 22 23 24 25 26 27 28 29 40 41 42 43 44 45
46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63
64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 90 91
92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109
110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127
128 129 140 141 142 143 144 145 146 147 148 149]
Test: index=[ 30 31 32 33 34 35 36 37 38 39 80 81 82 83 84 85 86 87
88 89 130 131 132 133 134 135 136 137 138 139]
Accuracy : 1.0
K-Fold 5
Train: index=[ 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35
36 37 38 39 50 51 52 53 54 55 56 57 58 59 60 61 62 63
64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81
82 83 84 85 86 87 88 89 100 101 102 103 104 105 106 107 108 109
110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127
128 129 130 131 132 133 134 135 136 137 138 139]
Test: index=[ 40 41 42 43 44 45 46 47 48 49 90 91 92 93 94 95 96 97
98 99 140 141 142 143 144 145 146 147 148 149]
Accuracy : 1.0
Average Accuracy : 0.9666666666666668
|
Leave-one-out Cross Validation
- 1개의 샘플에 대해서 평가를 진행한다.
- 데이터가 부족할 시 활용한다.
1
2
| from sklearn.model_selection import LeaveOneOut
from sklearn.model_selection import train_test_split
|
1
2
3
4
5
6
7
| # 데이터 갯수 줄이기
min_data, _, min_label, _ = train_test_split(data, label, test_size = 0.9, stratify=label, random_state=1004)
loo = LeaveOneOut()
loo.get_n_splits(min_data)
print(loo)
print(min_data.shape)
|
1
2
| LeaveOneOut()
(15, 4)
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| loo_accuracy = []
for idx, (train_index, validation_index) in enumerate(loo.split(min_data)):
print(f"Fold {idx+1}")
x_train, y_train = min_data[train_index], min_label[train_index]
x_valid, y_valid = min_data[validation_index], min_label[validation_index]
dt.fit(x_train, y_train)
pred = dt.predict(x_valid)
acc = accuracy_score(y_valid, pred)
loo_accuracy.append(acc)
print(f" Train: index={train_index}")
print(f" Test: index={validation_index}")
print(f"Accuracy : {acc}")
print(f"Average Accuracy : {np.mean(loo_accuracy)}")
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
| Fold 0
Train: index=[ 1 2 3 4 5 6 7 8 9 10 11 12 13 14]
Test: index=[0]
Accuracy : 1.0
Fold 1
Train: index=[ 0 2 3 4 5 6 7 8 9 10 11 12 13 14]
Test: index=[1]
Accuracy : 1.0
Fold 2
Train: index=[ 0 1 3 4 5 6 7 8 9 10 11 12 13 14]
Test: index=[2]
Accuracy : 1.0
Fold 3
Train: index=[ 0 1 2 4 5 6 7 8 9 10 11 12 13 14]
Test: index=[3]
Accuracy : 0.0
Fold 4
Train: index=[ 0 1 2 3 5 6 7 8 9 10 11 12 13 14]
Test: index=[4]
Accuracy : 1.0
Fold 5
Train: index=[ 0 1 2 3 4 6 7 8 9 10 11 12 13 14]
Test: index=[5]
Accuracy : 1.0
Fold 6
Train: index=[ 0 1 2 3 4 5 7 8 9 10 11 12 13 14]
Test: index=[6]
Accuracy : 0.0
Fold 7
Train: index=[ 0 1 2 3 4 5 6 8 9 10 11 12 13 14]
Test: index=[7]
Accuracy : 1.0
Fold 8
Train: index=[ 0 1 2 3 4 5 6 7 9 10 11 12 13 14]
Test: index=[8]
Accuracy : 1.0
Fold 9
Train: index=[ 0 1 2 3 4 5 6 7 8 10 11 12 13 14]
Test: index=[9]
Accuracy : 1.0
Fold 10
Train: index=[ 0 1 2 3 4 5 6 7 8 9 11 12 13 14]
Test: index=[10]
Accuracy : 1.0
Fold 11
Train: index=[ 0 1 2 3 4 5 6 7 8 9 10 12 13 14]
Test: index=[11]
Accuracy : 1.0
Fold 12
Train: index=[ 0 1 2 3 4 5 6 7 8 9 10 11 13 14]
Test: index=[12]
Accuracy : 1.0
Fold 13
Train: index=[ 0 1 2 3 4 5 6 7 8 9 10 11 12 14]
Test: index=[13]
Accuracy : 1.0
Fold 14
Train: index=[ 0 1 2 3 4 5 6 7 8 9 10 11 12 13]
Test: index=[14]
Accuracy : 1.0
Average Accuracy : 0.8666666666666667
|
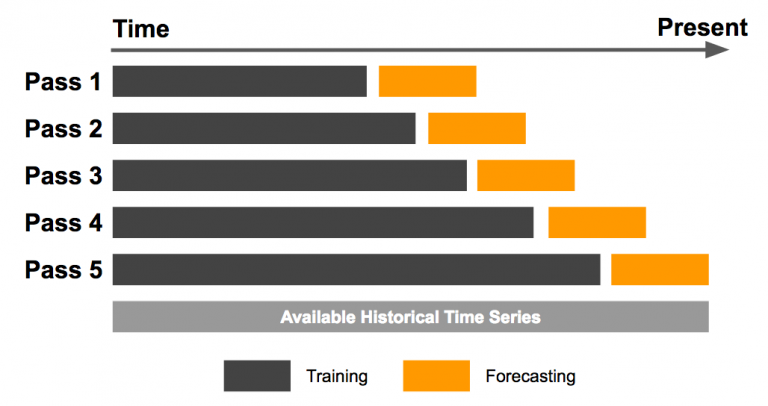
시간 순서가 있는 데이터 셋
- 시간의 Test 데이터가 현재의 시점이 되어야 하며, Test 데이터는 Train, validation 데이터보다 앞에 있으면 안된다.
Expanding Window
- K-Fold를 나누어 처음부터 점진적으로 크기를 늘려가며 Train으로 선정하고 모델을 학습하고 평가하는 방법
1
2
3
4
5
6
7
8
9
10
11
12
| def expanding_window(data, label, n_splits = 5):
train_test_splits = []
split_sizes_data = np.linspace(1, len(data), n_splits + 2, dtype=int)
split_sizes = split_sizes_data[1:n_splits + 1]
step = split_sizes_data[0]
for end in split_sizes:
x_train, y_train = data[:end], label[:end]
x_valid, y_valid = data[end:end+step+1], label[end:end+step+1]
train_test_splits.append((x_train, y_train, x_valid, y_valid))
return train_test_splits
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| expanding_splits = expanding_window(data, label, n_splits=5)
expanding_score = []
for idx, (x_train, y_train, x_valid, y_valid) in enumerate(expanding_splits):
print(f"Fold {idx+1}")
dt.fit(x_train, y_train)
pred = dt.predict(x_valid)
acc = accuracy_score(y_valid, pred)
expanding_score.append(acc)
print(f"Train Size : {x_train.shape}")
print(f"Accuracy : {acc}")
print(f"Average Accuracy : {np.mean(expanding_score)}")
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| Fold 1
Train Size : (25, 4)
Accuracy : 1.0
Fold 2
Train Size : (50, 4)
Accuracy : 0.0
Fold 3
Train Size : (75, 4)
Accuracy : 1.0
Fold 4
Train Size : (100, 4)
Accuracy : 0.0
Fold 5
Train Size : (125, 4)
Accuracy : 1.0
Average Accuracy : 0.6
|
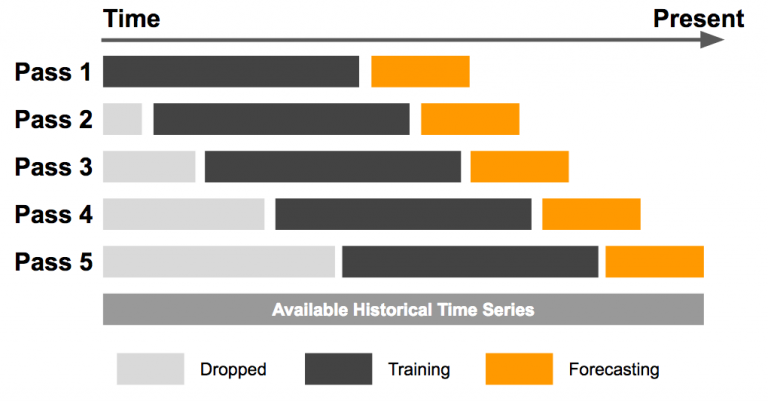
Sliding Window
- 고정된 크기의 윈도우를 일정 간격으로 이동하면서 모델을 학습하고 평가하는 방법
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| def sliding_window(data, lable, n_splits = 5):
train_test_splits = []
split_sizes = np.linspace(0, len(data), n_splits + 2, dtype=int)
for idx in range(1, n_splits+1):
start = split_sizes[idx-1]
end = split_sizes[idx]
test_end = split_sizes[idx+1]+1
x_train, y_train = data[start:end], label[start:end]
x_valid, y_valid = data[end:test_end], label[end:test_end]
train_test_splits.append((x_train, y_train, x_valid, y_valid))
return train_test_splits
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| sliding_splits = sliding_window(data, label, n_splits=5)
sliding_score = []
for idx, (x_train, y_train, x_valid, y_valid) in enumerate(sliding_splits):
print(f"Fold {idx+1}")
dt.fit(x_train, y_train)
pred = dt.predict(x_valid)
acc = accuracy_score(y_valid, pred)
sliding_score.append(acc)
print(f"Train Size : {x_train.shape}")
print(f"Accuracy : {acc}")
print(f"Average Accuracy : {np.mean(sliding_score)}")
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| Fold 1
Train Size : (25, 4)
Accuracy : 0.9615384615384616
Fold 2
Train Size : (25, 4)
Accuracy : 0.0
Fold 3
Train Size : (25, 4)
Accuracy : 0.9615384615384616
Fold 4
Train Size : (25, 4)
Accuracy : 0.0
Fold 5
Train Size : (25, 4)
Accuracy : 1.0
Average Accuracy : 0.5846153846153846
|