[Data Engineering] Elastic Search란?
Elastic Search란 무엇인가
Elasticsearch란?
Elasticsearch는 빠르고 확장성이 뛰어난 오픈소스 분산 검색 및 분석 엔진입니다. 모든 유형의 데이터를 저장, 검색, 분석하는 데 사용할 수 있으며, 이는 텍스트, 숫자, 위치 정보, 구조화된 데이터 및 비정형 데이터를 포함합니다.
Elasticsearch는 Apache Lucene(자바 언어로 이루어진 정보 검색 가이브러리)을 기반으로 구축되었으며, 2010년에 처음 출시된 이후로 세계에서 가장 널리 사용되는 검색 엔진 중 하나가 되었습니다. 애플리케이션에서 실시간 검색 및 분석이 필요할 때 자주 사용됩니다.
Elasticsearch의 특징
분산 아키텍처
Elasticsearch는 클러스터로 실행되며 데이터를 여러 노드에 분산시켜 높은 가용성과 확장성을 제공합니다.
빠른 검색 성능
역색인(Inverted Index)과 다양한 최적화 기법을 활용해 대량의 데이터를 빠르게 검색할 수 있습니다.
RESTful API 지원
Elasticsearch는 JSON 기반의 RESTful API를 제공하여 다양한 프로그래밍 언어 및 시스템과 쉽게 연동할 수 있습니다.
다양한 데이터 유형 처리
텍스트, 숫자, 날짜, 위치 정보 등 다양한 유형의 데이터를 저장하고 검색할 수 있습니다.
실시간 데이터 분석
강력한 집계(aggregation) 기능을 제공하여 데이터를 실시간으로 분석할 수 있습니다.
Elasticsearch의 주요 사용 사례
로그 및 이벤트 데이터 분석
대량의 로그 데이터를 수집, 저장, 분석하여 시스템 성능 모니터링 및 문제 해결에 활용됩니다.
검색 엔진 구축
웹사이트, 애플리케이션, 문서 저장소 등에서 강력한 검색 기능을 제공하는 데 사용됩니다.
비즈니스 분석 및 데이터 시각화
Kibana와 함께 사용하여 데이터를 시각적으로 분석하고 인사이트를 도출할 수 있습니다.
보안 및 위협 탐지
보안 이벤트 데이터를 분석하여 이상 징후를 탐지하고 보안 위협을 예방하는 데 활용됩니다.
Elasticsearch는 단독으로 사용될 수도 있지만, 일반적으로 Elastic Stack(ELK Stack)의 일부로 사용됩니다. ELK Stack은 Elasticsearch, Logstash(데이터 수집), Kibana(데이터 시각화)로 구성되어 있으며, 추가적으로 Beats(경량 데이터 수집기)와 함께 확장될 수 있습니다.
Elasticsearch는 뛰어난 성능과 확장성을 갖춘 검색 및 분석 엔진으로, 다양한 산업과 애플리케이션에서 활용되고 있습니다.
Elasticsearch 아키텍쳐
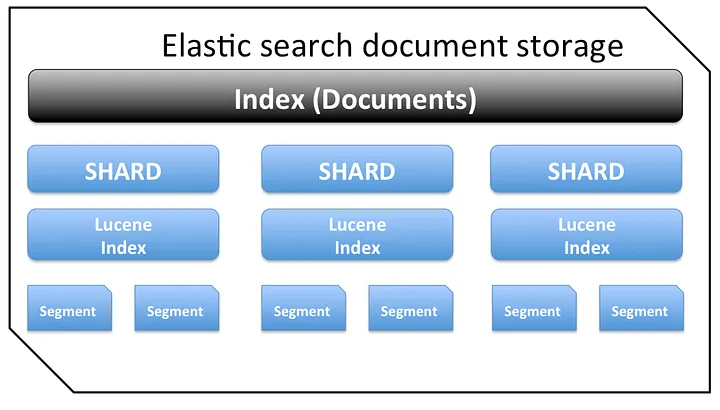
- 인덱스(index)
- 데이터 저장 공간
- 단일 데이터 단위가 Document, Document의 집합이 인덱스 하나의 인덱스가 여러 노드에 분산 저장(M:N)
- 샤드(shard)
- 색인된 문서는 하나의 인덱스 — 인덱스 내부에 색인된 데이터는 여러개의 파티션으로 나뉘어 구성(파티션 = 샤드)
- 인덱스의 저장 단위, 노드에 분산되어 저장
- 타입(type)
- 인텍스의 논리적 구조
- 6.1부터 인덱스 당 하나의 타입을 제공
- (index == type)
- 문서(Document)
- 데이터가 저장되는 최소 단위
- 한 문서는 다수의 필드로 구성
- nested 구조를 지원
- 필드(filed)
- 문서를 구성하는 속성
- Column과 비슷한 개념
- 하나의 필드에 여러 데이터 타입을 가질 수 있음
- 매핑(mapping)
- 문서의 필드와 필드의 속성을 정의, 인덱싱 방법을 정의
- 인텍스 매핑에서는 여러 데이터 타입이 지정 가능하지만 필드명은 중복사용 불가
Elasticsearch Cluster, Node
- 클러스터(Cluster)
- 노드의 집합
- 모든 노드를 포괄하는 통합 색인화 및 검색 기능 제공
- 고유 이름 가짐
- 클러스터에 하나 이상의 노드를 가짐
- 노드(Node)
- Elasticsearch를 구성하는 서버
- 데이터를 저장하고 클러스터의 indexing 및 검색 기능
- 노드에도 고유한 이름 존재(기본적으로 UUID)
Node Type
- 마스터 노드(Master Node)
- 클러스터 상태 정보 관리
- 지연이 없고 네트워크 가용성이 좋은 노드여야 함
- 기존 마스터 노드가 다운되면, 다른 마스터 후보 노드 중 하나가 마스터 노드로 선출되어 마스터 노드의 역할을 대신 수행
- 마스터 노드는 하나, 최소 마스터 노드 대수 설정 필요(Split Brain)
- 데이터 노드(Data Node)
- 실질적인 데이터 저장: 문서가 저장되는 노드, 샤드가 배치됨
- 검색과 통계 등 데이터 관련 작업 수행: 색인 작업은 CPU, 메모리, 스토리 등 컴퓨터 리소스를 많이 소요하므로 리소스 모니터링 필수
- 인덱싱할 문서가 많다면 마스터 노드와 분리하는 것을 추천
- 코디네이팅 노드(Coordinating Node)
- 들어오는 요청을 분산시켜주는 노드(Round-Robin)
- 클러스터 관련 요청은 마스터 노드, 데이터 관련 요청은 데이터 노드로 전달
- 인제스트 노드(Ingest Node)
- 색인 전에 데이터를 전처리
- 데이터 포맷 변경을 위해서 스크립트로 파이프라인을 구성할 수 있음
- 인덱스 생성 전 문서의 형식을 다양하게 변경할 수 있음
Split Brain
- 마스터 후보 노드간 네트워크가 단절되었을 때 각각의 마스터 후보 노드가 마스터로 승격, 두 개의 클러스터로 나뉘어 독립적으로 동작하는 현상
- 양쪽 클러스터에서 각각 데이터 쓰기, 업데이트가 이루어지면 네트워크가 복구되어도 마스터가 따로 존재하기 때문에 데이터 비동기 문제로 데이터의 문제가 발생
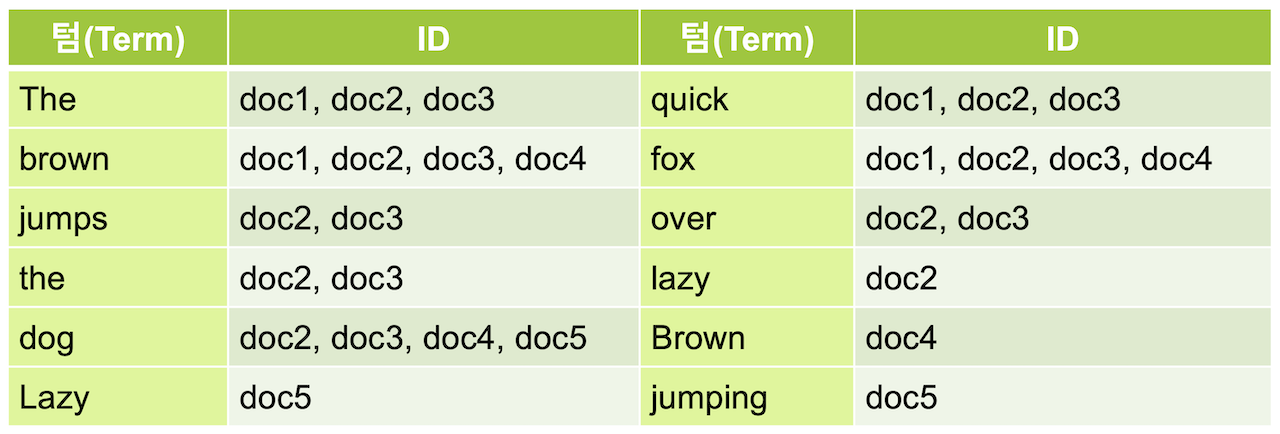
역 인덱스(Inverted Index)란?
기존의 RDB는 전체 Row를 탐색하여 찾고자하는 단어를 포함하는 데이터를 찾아나갔습니다.

RDB는 위와 같이 like 검색을 사용하기 때문에 데이터가 늘어날수록 탐색해야할 대상이 늘어나 시간이 오래걸리게 됩니다.
Elastic Search는 데이터를 저장할 때 아래와 같은 역 인덱스(inverted index) 라는 구조를 만들어 저장합니다.
Elasticsearch의 단점
- 실시간 데이터 전송 불가
- 인덱싱 된 데이터는 1초 뒤에 검색 가능
- Near Real Time
- 트랜잭션, 롤백 불가
- 리소스 소모가 큰 롤백이나 트랜잭션을 지원하지 않음.(데이터 손실 위험)
- 데이터 업데이트 불가
- 업데이트는 기존 문서 삭제하고 변경내용을 새 문서를 생성하는, reindexing방식 사용. 비용이 큼
참고자료