[MLOps] GCP VertexAI 1(BigQuery)
VertexAI에서 BigQuery의 데이터 불러오기
[MLOps] GCP VertexAI 1(BigQuery)
![]()
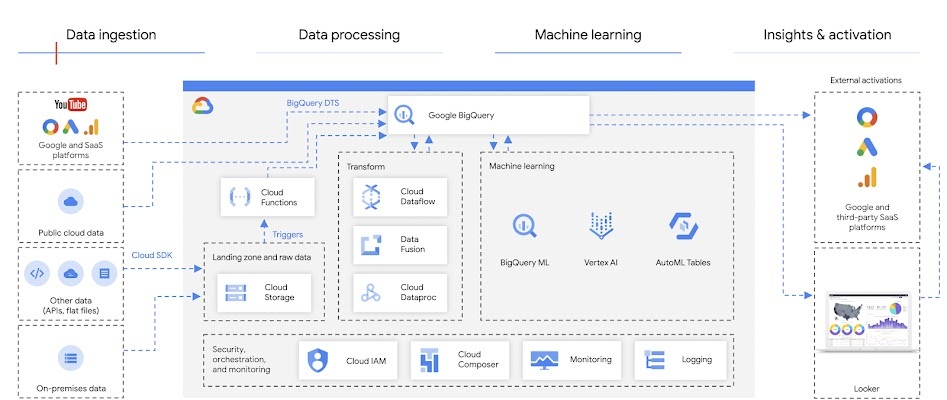
BigQuery
- 개요: Serverless로 구성된 대용량 데이터 웨어하우스 및 분석 플랫폼
- 특징
- SQL 기반의 강력한 쿼리 기능 제공
- 대용량 데이터셋을 실시간으로 분석할 수 있는 높은 성능
- 서버리스 아키텍처로 인프라 관리 부담 없음
- 외부 데이터 소스와 쉽게 통합 가능
데이터 분석의 변화에 적합한 구조

- 전통적 데이터베이스의 한계 극복
- BigQuery는 Serverless 구조로 확장이 쉽고 실시간 데이터 분석 가능
- 대용량 데이터셋에서도 높은 성능 제공
- 인프라 관리의 간소화
- 서버 관리 없이 자동 스케일링
- 대용량 데이터셋에 대해서도 빠르고 효율적인 쿼리 수행 가능
- 다양한 데이터 소스 통합
- 여러 데이터 파이프라인 및 Google Cloud 서비스와 자연스럽게 연동
- 데이터 수집부터 분석까지 하나의 흐름으로 처리 가능
쉬운 분석과 다양한 데이터 지원
- 시각화 도구와의 강력한 연동
- Google Data Studio, Looker 등과 연계 가능
- SQL 기반으로 즉각적인 시각화 분석 수행
- 다양한 데이터 포맷 지원
- JSON, Avro, Parquet 등 다양한 형식 지원
- 여러 데이터 소스로부터 유연하게 데이터 수집 가능
- 유연한 스키마 처리
- 스키마가 정의되지 않은 데이터도 쿼리 가능
- 반정형 / 비정형 데이터 분석에 적합
VertexAI에서 BigQuery 데이터 불러오기
방법 1
- SQL query를 통해 데이터를 전처리하고 불러오기
방법 2
- bpd 라이브러리(bigframes.pandas)을 사용하여 데이터 불러오기 -> pandas형식으로 전처리
해당 방법은 방법1을 바탕으로 작성하였다.
데이터는 bigquery public에 있는 london_bicycles의 cycle_stations와 cycle_hire를 사용하였다.
1
2
3
4
5
6
7
8
9
import torch
import torch.nn as nn
from torch.utils.data import TensorDataset, DataLoader
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
from datetime import datetime
import pandas as pd
import numpy as np
1
2
from google.cloud.bigquery import Client, QueryJobConfig
client = Client()
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
query="""WITH staging AS (
SELECT
STRUCT(
start_stn.name,
ST_GEOGPOINT(start_stn.longitude, start_stn.latitude) AS POINT,
start_stn.docks_count,
start_stn.install_date
) AS starting,
STRUCT(
end_stn.name,
ST_GEOGPOINT(end_stn.longitude, end_stn.latitude) AS point,
end_stn.docks_count,
end_stn.install_date
) AS ending,
STRUCT(
rental_id,
bike_id,
duration, --seconds
ST_DISTANCE(
ST_GEOGPOINT(start_stn.longitude, start_stn.latitude),
ST_GEOGPOINT(end_stn.longitude, end_stn.latitude)
) AS distance, --meters
start_date,
end_date
) AS bike
FROM `bigquery-public-data.london_bicycles.cycle_stations` AS start_stn
LEFT JOIN `bigquery-public-data.london_bicycles.cycle_hire` AS b
ON start_stn.id = b.start_station_id
LEFT JOIN `bigquery-public-data.london_bicycles.cycle_stations` AS end_stn
on end_stn.id = b.end_station_id
LIMIT 100000)
SELECT * FROM staging
"""
job = client.query(query)
df = job.to_dataframe()
1
df.head()
| starting | ending | bike | |
|---|---|---|---|
| 0 | {'name': 'New Spring Gardens Walk, Vauxhall', ... | {'name': 'Broadley Terrace, Marylebone', 'poin... | {'rental_id': 118913498, 'bike_id': 21845, 'du... |
| 1 | {'name': 'New Spring Gardens Walk, Vauxhall', ... | {'name': 'Moor Street, Soho', 'point': 'POINT(... | {'rental_id': 106029120, 'bike_id': 12260, 'du... |
| 2 | {'name': 'New Spring Gardens Walk, Vauxhall', ... | {'name': 'Ethelburga Estate, Battersea Park', ... | {'rental_id': 79563236, 'bike_id': 10009, 'dur... |
| 3 | {'name': 'New Spring Gardens Walk, Vauxhall', ... | {'name': 'Northumberland Avenue, Strand', 'poi... | {'rental_id': 114066766, 'bike_id': 15247, 'du... |
| 4 | {'name': 'New Spring Gardens Walk, Vauxhall', ... | {'name': 'Doddington Grove, Kennington', 'poin... | {'rental_id': 78933280, 'bike_id': 9620, 'dura... |
1
2
3
4
5
6
values = df["bike"].values
duration = list(map(lambda x: x["duration"], values))
distance = list(map(lambda x: x["distance"], values))
dates = list(map(lambda x: x["start_date"], values))
data = pd.DataFrame(data = {"duration": duration, "distance": distance, "start_date": dates})
1
data = data.dropna()
1
data.head()
| duration | distance | start_date | |
|---|---|---|---|
| 0 | 1800.0 | 5051.961504 | 2022-04-13 17:09:00+00:00 |
| 1 | 780.0 | 2904.863984 | 2021-03-14 20:37:00+00:00 |
| 2 | 780.0 | 3136.325002 | 2018-08-22 18:33:00+00:00 |
| 3 | 780.0 | 2109.218317 | 2021-10-25 08:46:00+00:00 |
| 4 | 780.0 | 1371.888510 | 2018-08-05 13:55:00+00:00 |
1
data.info()
1
2
3
4
5
6
7
8
9
10
<class 'pandas.core.frame.DataFrame'>
Index: 94480 entries, 0 to 99999
Data columns (total 3 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 duration 94480 non-null float64
1 distance 94480 non-null float64
2 start_date 94480 non-null datetime64[ns, UTC]
dtypes: datetime64[ns, UTC](1), float64(2)
memory usage: 2.9 MB
1
2
3
4
5
6
# start_date -> weekday, hour
# duration -> minute
data["weekday"] = data["start_date"].apply(lambda x: x.weekday())
data["hour"] = data["start_date"].apply(lambda x: x.time().hour)
data.drop(columns=["start_date"], inplace=True)
1
data["duration"] = data["duration"].apply(lambda x: float(x/60))
1
data.head()
| duration | distance | weekday | hour | |
|---|---|---|---|---|
| 0 | 30.0 | 5051.961504 | 2 | 17 |
| 1 | 13.0 | 2904.863984 | 6 | 20 |
| 2 | 13.0 | 3136.325002 | 2 | 18 |
| 3 | 13.0 | 2109.218317 | 0 | 8 |
| 4 | 13.0 | 1371.888510 | 6 | 13 |
1
2
3
4
# weekday, hour -> one-hot
# distance -> Normalization
data = pd.get_dummies(data, columns = ["weekday", "hour"], prefix = ["weekday", "hour"])
1
2
X = data.drop(["duration"],axis=1).to_numpy()
y = data["duration"].to_numpy().reshape(-1,1)
MLP 테스트
bigquery에서 추출한 데이터를 MLP모델에 학습하였다.
1
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2, shuffle=True, random_state=1004)
1
2
3
4
X_train = torch.FloatTensor(X_train)
X_test = torch.FloatTensor(X_test)
y_train = torch.FloatTensor(y_train)
y_test = torch.FloatTensor(y_test)
1
2
3
4
5
6
7
8
train_loader = DataLoader(
TensorDataset(X_train, y_train),
batch_size = 256, shuffle=True
)
val_loader = DataLoader(
TensorDataset(X_test, y_test),
batch_size = 256, shuffle=False
)
1
2
3
4
5
6
7
8
9
10
11
class MLP(nn.Module):
def __init__(self, in_dim):
super().__init__()
self.layer = nn.Sequential(
nn.Linear(in_dim, 64),
nn.ReLU(),
nn.Linear(64, 1)
)
def forward(self, x):
return self.layer(x)
1
2
in_dim = X_train.size()[1]
model = MLP(in_dim)
1
2
criterion = nn.MSELoss()
optimizer = torch.optim.Adam(model.parameters(), lr=1e-3)
1
2
3
4
5
6
7
8
9
10
def evaluate(model, loader, criterion):
model.eval()
total_loss, n = 0.0, 0
with torch.no_grad():
for xb, yb in loader:
pred = model(xb)
loss = criterion(pred, yb)
total_loss += loss.item() * xb.size(0)
n += xb.size(0)
return total_loss / max(n, 1)
1
2
3
4
5
6
7
8
9
10
11
12
13
epochs = 5
for epoch in range(epochs):
model.train()
total_loss, n = 0.0, 0
for xb, yb in train_loader:
pred = model(xb)
loss = criterion(pred, yb)
optimizer.zero_grad()
loss.backward()
optimizer.step()
이 기사는 저작권자의 CC BY 4.0 라이센스를 따릅니다.