[MLOps] MLFlow 실습
MLOps를 위한 MLFlow 실습
[MLOps] MLFlow 실습
MLFlow 구축
1
2
# MLFlow 설치 및 환경 구축
!pip install mlflow
Terminal에 아래와 같이 작성하면 MLFlow 실행
1
mlflow ui
INFO:waitress:Serving on http://127.0.0.1:5000
위 주소 클릭 -> 실행
머신러닝
자동 로깅
Sklearn 머신러닝을 사용하는 경우 mlflow.sklearn.autolog()를 사용할 수 있다. 해당 기능은 매개변수를 자동 로깅 통합 기능을 제공하다.
자세한 mlflow.autolog()는 MLflow Python API를 통해 확인할 수 있다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
import mlflow
from sklearn.datasets import load_diabetes
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn.ensemble import RandomForestRegressor
# tracing저장 경로
mlflow.set_tracking_uri("file:./mlruns")
# 실험 환경 설정
mlflow.set_experiment("diabetes-rf")
# 자동 로깅
mlflow.sklearn.autolog()
data_diabetes = load_diabetes()
X_train, X_test, y_train, y_test = train_test_split(data_diabetes.data, data_diabetes.target, test_size = 0.2, random_state = 1004)
reg = GridSearchCV(RandomForestRegressor(), {"n_estimators": [50,100], "max_depth": [2,5,10], "max_features": [5,8,10]})
reg.fit(X_train, y_train)
predictions = reg.predict(X_test)
1
2
2025/12/22 17:27:09 INFO mlflow.utils.autologging_utils: Created MLflow autologging run with ID 'b854a7f39b034877969c0579904195f9', which will track hyperparameters, performance metrics, model artifacts, and lineage information for the current sklearn workflow
2025/12/22 17:27:20 INFO mlflow.sklearn.utils: Logging the 5 best runs, 13 runs will be omitted.
수동 로깅
mlflow.log_metric(), mlflow.log_metrics(): metric를 지정해서 로깅, metrics의 경우 dict형태로 저장 mlflow.log_param(), mlflow.log_params(): param을 지정해서 로깅, params의 경우 dict형태로 저장
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
from sklearn.metrics import mean_absolute_error, mean_squared_error
def train_model_with_hyperparameters(n_estimator, max_depth, max_feature):
with mlflow.start_run():
model = RandomForestRegressor(n_estimators=n_estimator, max_depth=max_depth, max_features=max_feature)
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
mae = mean_absolute_error(y_test, y_pred)
mse = mean_squared_error(y_test, y_pred)
mlflow.log_param("n_estimators", n_estimator)
mlflow.log_param("max_depth", max_depth)
mlflow.log_param("max_features", max_feature)
mlflow.log_metric("mae_on_test", mae)
mlflow.log_metric("mse_on_test", mse)
mlflow.log_metric("rmse_on_test", mse**0.5)
1
2
3
4
5
6
7
8
n_estimators = [50,100]
max_depths = [2,5,10]
max_features = [5,8,10]
for n_estimator in n_estimators:
for max_depth in max_depths:
for max_feature in max_features:
train_model_with_hyperparameters(n_estimator, max_depth, max_feature)
Experiments
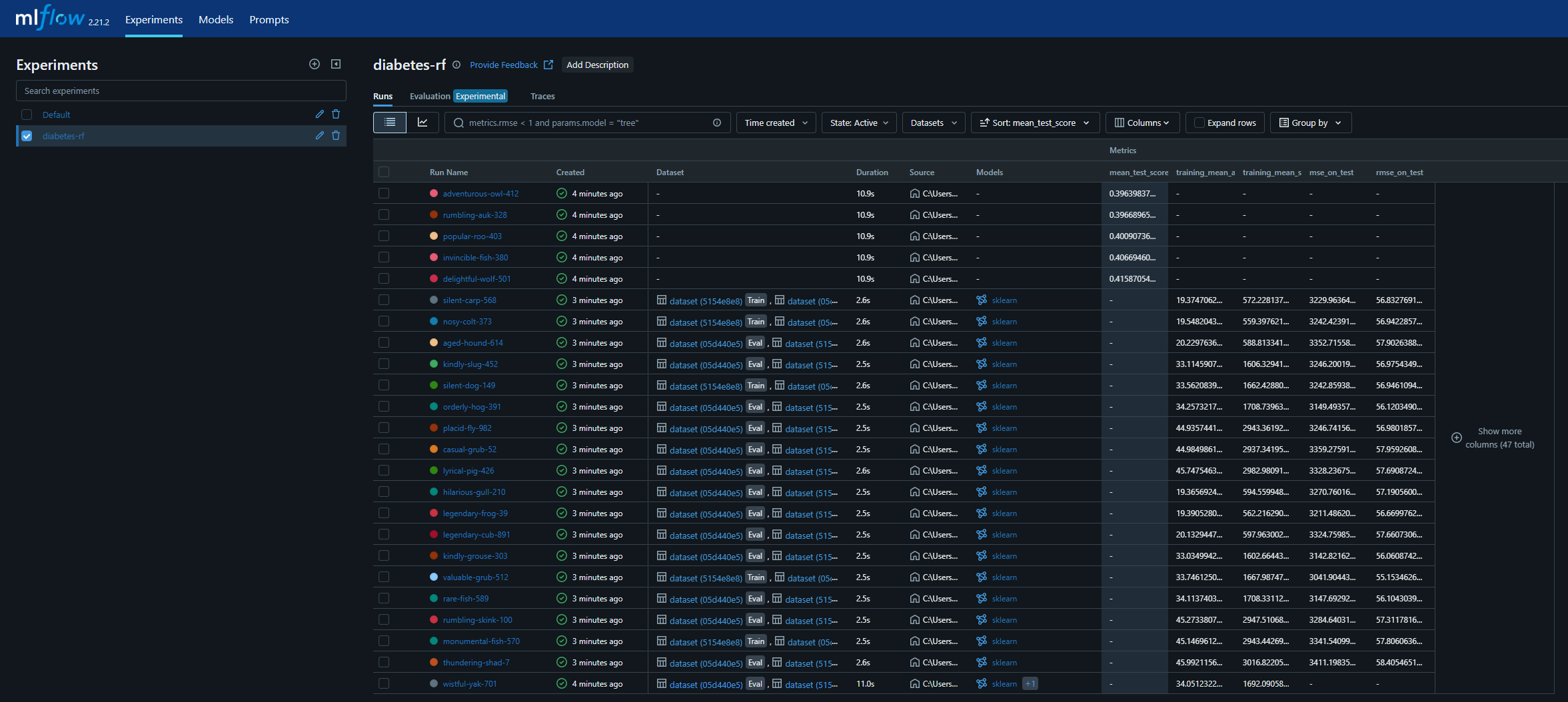
- 만들어진 log를 확인하여 모델 선택
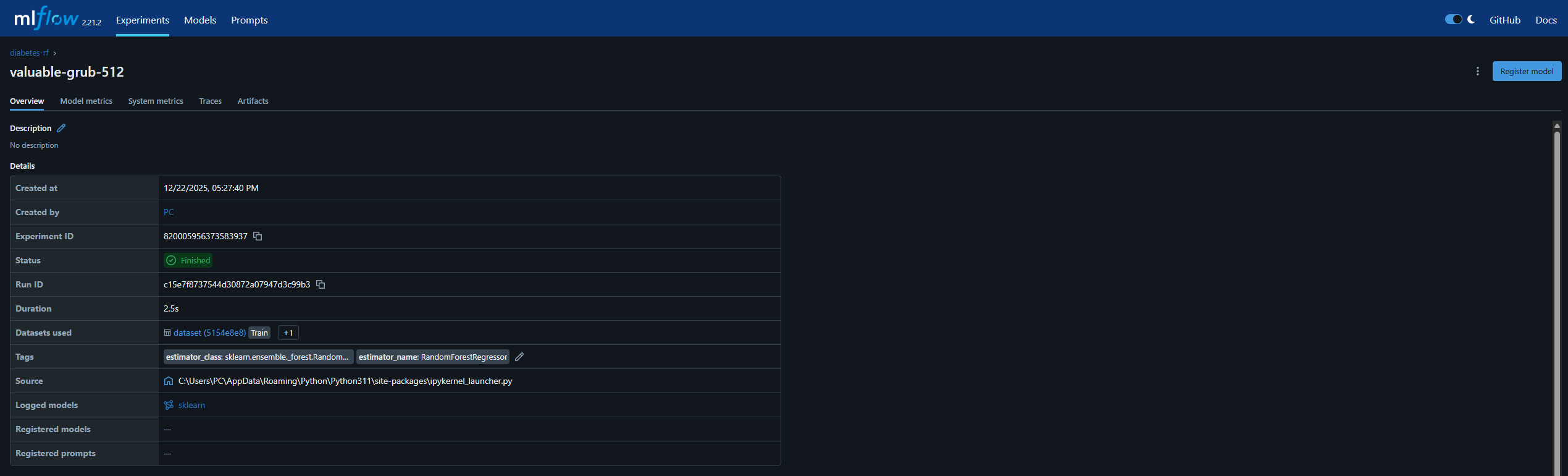
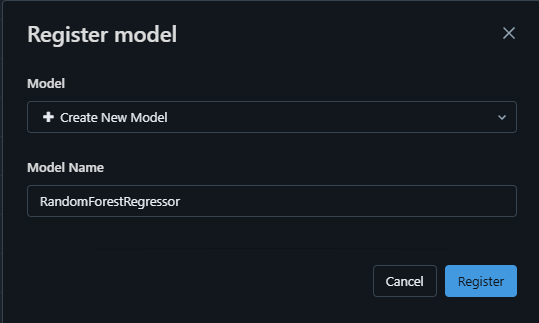
- model을 register에 저장

- version1으로 새로운 모델 생성
※ 구버전과 신버전의 차이가 있음
신버전
Tags와Aliases로 모델 배포
구버전
stage의Archived,Staging,Production으로 관리 및 배포Archived: 저장 상태Staging: QA 테스트 상태(준비 상태)Production: 배포 상태
Model Serving
- 배포된 모델이 예측 요청을 받고 처리하여 예측 결과를 반환하는 과정을 의미
- 요청 처리와 모델 추론
방법 1
1
2
3
import mlflow
mlflow.set_tracking_uri("http://127.0.0.1:5000")
1
2
3
model_url = "models:/RandomForestRegressor/1"
loaded_model = mlflow.sklearn.load_model(model_url)
1
loaded_model
RandomForestRegressor(max_depth=5, max_features=8, n_estimators=50)In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook.
On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
RandomForestRegressor(max_depth=5, max_features=8, n_estimators=50)
1
2
y_pred = loaded_model.predict(X_test)
mean_squared_error(y_pred, y_test)
1
3041.9044368258315
방법 2
CLI를 통해 모델을 지정된 포트로 서버 통신
1
mlflow models serve -m models:/RandomForestRegressor/1 -p 5001 --no-conda
1
2
3
4
5
6
7
8
9
10
11
import pandas as pd
import requests
host = "127.0.0.1"
url = f"http://{host}:5001/invocations"
X_test_df = pd.DataFrame(X_test, columns=data_diabetes.feature_names)
json_data = {"dataframe_split": X_test_df[:10].to_dict(orient="split")}
response = requests.post(url, json=json_data)
print(f"\nPyfunc 'predict_interval':\n${response.json()}")
1
2
Pyfunc 'predict_interval':
${'predictions': [116.08085576971826, 100.81009133456911, 184.35325437343346, 104.71531717642706, 156.09652462733177, 174.07622265563091, 125.68893595239533, 140.11980756904265, 81.71646235903134, 200.24981584985514]}
Cloud 배포
AWS Sagemaker
1
2
mlflow sagemaker build-and-push-container -m models:/<model_id>
mlflow sagemaker deploy {parameters}
AzureML
1
mlflow azureml export -m {model' path} -o test-output
딥러닝
model.pytorch.autolog()가 가능하지만 수동으로 하는 것을 권장
1
2
3
4
5
6
7
8
9
10
11
import mlflow
from torch.utils.data import Dataset, DataLoader
from torchvision import datasets
from torchvision.transforms import ToTensor
from torchvision.io import read_image
import torch
import torch.nn as nn
import pandas as pd
import os
1
2
3
4
5
def seed_everything(seed=42):
torch.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = False
1
2
3
4
5
mlflow.set_tracking_uri("file:./mlruns")
mlflow.set_experiment("FashionCNN")
# mlflow.pytorch.autolog()
1
<Experiment: artifact_location=('file:///c:/Users/PC/Desktop/실습/mlruns/107038616652530463'), creation_time=1766485896982, experiment_id='107038616652530463', last_update_time=1766485896982, lifecycle_stage='active', name='FashionCNN', tags={'mlflow.experimentKind': 'custom_model_development'}>
1
2
3
4
5
6
7
8
9
10
11
12
13
training_data = datasets.FashionMNIST(
root="data",
train=True,
download=False,
transform=ToTensor()
)
test_data = datasets.FashionMNIST(
root="data",
train=False,
download=False,
transform=ToTensor()
)
1
2
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print(device)
1
cuda:0
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
class FashionDataset(Dataset):
def __init__(self, annotations_file, img_dir, transform=None, target_transform=None):
self.img_labels = pd.read_csv(annotations_file, names=["file_name", "label"])
self.img_dir = img_dir
self.transform = transform
self.target_transform = target_transform
def __len__(self):
return len(self.img_labels)
def __getitem__(self, idx):
img_path = os.path.join(self.img_dir, self.img_labels.iloc[idx, 0])
image = read_image(img_path)
label = self.img_labels.iloc[idx, 1]
if self.transform:
image = self.transform(image)
if self.target_transform:
label = self.target_transform(label)
return image, label
1
2
train_dataloader = DataLoader(training_data, batch_size=64, shuffle=True)
test_dataloader = DataLoader(test_data, batch_size=64, shuffle=True)
1
2
a = next(iter(train_dataloader))
a[0].size()
1
torch.Size([64, 1, 28, 28])
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
class FashionCNN(nn.Module):
def __init__(self):
super(FashionCNN, self).__init__()
self.layer1 = nn.Sequential(
nn.Conv2d(in_channels=1, out_channels=32, kernel_size=3, padding=1),
nn.BatchNorm2d(32),
nn.MaxPool2d(kernel_size=2, stride=2)
)
self.layer2 = nn.Sequential(
nn.Conv2d(in_channels=32, out_channels=64, kernel_size=3),
nn.BatchNorm2d(64),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2)
)
self.fc1 = nn.Linear(in_features=64*6*6, out_features=600)
self.drop = nn.Dropout(0.25)
self.fc2 = nn.Linear(in_features=600, out_features=120)
self.fc3 = nn.Linear(in_features=120, out_features=10)
def forward(self, x):
out = self.layer1(x)
out = self.layer2(out)
out = out.view(out.size(0), -1)
out = self.fc1(out)
out = self.drop(out)
out = self.fc2(out)
out = self.fc3(out)
return out
1
2
3
4
5
params = {
"epochs": 5,
"learning_rate": 0.001,
"batch_size": 64
}
1
2
3
4
5
6
7
8
model = FashionCNN()
model.to(device)
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=params["learning_rate"])
print(model)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
FashionCNN(
(layer1): Sequential(
(0): Conv2d(1, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(layer2): Sequential(
(0): Conv2d(32, 64, kernel_size=(3, 3), stride=(1, 1))
(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU()
(3): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(fc1): Linear(in_features=2304, out_features=600, bias=True)
(drop): Dropout(p=0.25, inplace=False)
(fc2): Linear(in_features=600, out_features=120, bias=True)
(fc3): Linear(in_features=120, out_features=10, bias=True)
)
1
2
3
4
5
6
7
8
9
10
11
@torch.no_grad()
def compute_accuracy_from_loader(model, dataloader, device):
model.eval()
correct, total = 0, 0
for data, target in dataloader:
data, target = data.to(device), target.to(device)
logits = model(data)
pred = logits.argmax(dim=1)
correct += (pred == target).sum().item()
total += target.size(0)
return correct / max(total, 1)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
best_model_id = None
best_test_acc = -1.0
with mlflow.start_run() as run:
mlflow.log_params(params)
for epoch in range(params["epochs"]):
model.train()
for data, target in train_dataloader:
data, target = data.to(device), target.to(device)
output = model(data)
loss = criterion(output, target)
optimizer.zero_grad()
loss.backward()
optimizer.step()
model_info = mlflow.pytorch.log_model(
pytorch_model=model,
name=f"checkpoint-{epoch}",
step=epoch,
pip_requirements=[
"torch==2.6.0+cu124",
"torchvision==0.21.0+cu124",
"numpy",
],
)
train_acc = compute_accuracy_from_loader(model, train_dataloader, device)
test_acc = compute_accuracy_from_loader(model, test_dataloader, device)
mlflow.log_metric(
key="train_accuracy",
value=train_acc,
step=epoch,
model_id=model_info.model_id,
)
mlflow.log_metric(
key="test_accuracy",
value=test_acc,
step=epoch,
model_id=model_info.model_id,
)
if test_acc > best_test_acc:
best_test_acc = test_acc
best_model_id = model_info.model_id
ranked_checkpoints = mlflow.search_logged_models(
filter_string=f"source_run_id='{run.info.run_id}'",
order_by=[{"field_name": "metrics.test_accuracy", "ascending": False}],
output_format="list",
)
best_checkpoint = ranked_checkpoints[0]
print(f"Best checkpoint: {best_checkpoint.name}")
print(f"Accuracy: {best_checkpoint.metrics[0].value}")
best_model_uri = f"models:/{best_model_id}"
try:
mv = mlflow.register_model(model_uri=best_model_uri, name="FasionCNN_Model")
print("FashionCNN_model : ", mv.version)
except Exception as e:
print("error : ", e)
1
2
3
4
5
6
7
Best checkpoint: checkpoint-4
Accuracy: 0.9048
FashionCNN_model : 2
Registered model 'FasionCNN_Model' already exists. Creating a new version of this model...
Created version '2' of model 'FasionCNN_Model'.
이 기사는 저작권자의 CC BY 4.0 라이센스를 따릅니다.